You weren’t feeling well, so you went to your doctor. Based on training, years of experience, and a careful examination of your signs and symptoms, they order tests. The results come back: cancer. They refer you to a medical oncologist, who confirms the diagnosis and outlines a treatment plan, possibly in consultation with a surgeon and a radiological oncologist.
You trust the expertise of these medical professionals because you trust their knowledge.
However, you wouldn’t trust any of them to be the pilot for your flight to Tokyo. Or to determine the effects of complex economic sanctions. Or to plan a combined arms military campaign. Those tasks require entirely different sets of expertise.
For the most part, I think we all know this.
But consider that recent studies show some GPT models “competes with and surpasses the competencies of top-performing PhD students over 50% of the time”. (source) And even more impressively, it is compared to PhD level experts with the GPQA dataset.
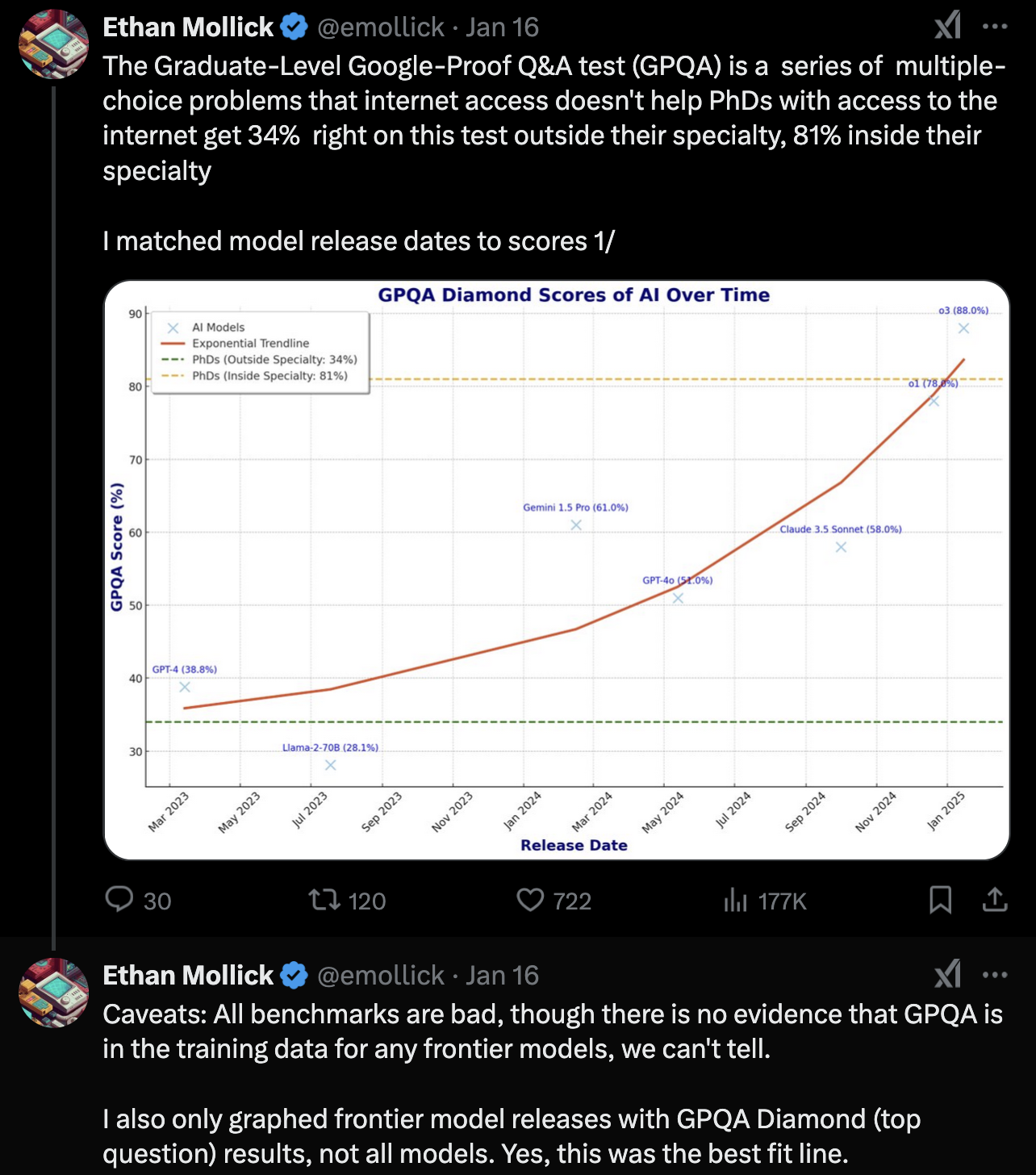
So what’s GPQA? Google-Proof Questions and Answers. From the arXiv abstract.
We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are "Google-proof"). The questions are also difficult for state-of-the-art AI systems, with our strongest GPT-4 based baseline achieving 39% accuracy. If we are to use future AI systems to help us answer very hard questions, for example, when developing new scientific knowledge, we need to develop scalable oversight methods that enable humans to supervise their outputs, which may be difficult even if the supervisors are themselves skilled and knowledgeable. The difficulty of GPQA both for skilled non-experts and frontier AI systems should enable realistic scalable oversight experiments, which we hope can help devise ways for human experts to reliably get truthful information from AI systems that surpass human capabilities.
It has ALL the PhDs.
But…
When you look at its code, you see that it has problems a PhD doesn’t have. Like limitations in context length. Like the inconsistency of answers. And an overconfidence regardless of recent mistakes. It will confidently present non-functioning code … however many times in a row, each time with the same authoritative tone. And when those errors get pointed out, each will have the same fake empathy, a new understanding of the problem (and answer)m and the same confidence in yet another non-functional piece of code.
Argumentum ad verecundiam, the argument from authority. And the thing is, it may. Do you have the requisite knowledge to evaluate statements in those (or any of it’s other) areas? I know I don’t.
But, while it may have the answers, things like a context limit also limits it performance. There are other things, too. I’d argue the training data for code LLMs is based on code repositories like GitHub or StackOverflow. A lot of that code is very good, a lot of it is bad; most it is just average though.
Put differently, at this point most LLM code generation is Regression to the Mean
What I do know is that LLMs can generate mountains of shitty code. But what’s needed isn’t necessarily a lot of code, but the right amount of good code.