Posts
Testing mathjax support …
This is the formula for Kullback-Leibler (hence the KL) divergence between two probability distributions. Essentially, its a way to measure the difference between the predicted probability distribution the \(hat{y}\) and the true probability distribution \(y\). \begin{aligned} KL(\hat{y} || y) …
When Tableau won't behave
I haven’t fired up Tableau in a while as I’ve been working on other things. I did however update it with homebrew a couple of days ago and was immediately met with an error message so long that it couldn’t generate a response from duckduckgo other than how it was too long. The gist …
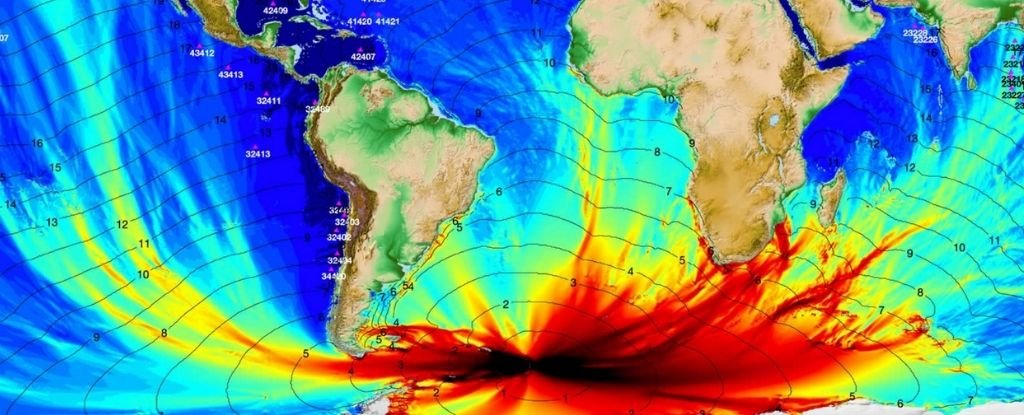
When was the last …
In preparation for building a model for earthquake initiated tsunami prediction, my thinking is what is needed data on earthquakes, tsunami, and ideally which earthquakes generated tsunami warnings as a check. No surprises here. But that got me wondering when was the last tsunami which there was no …
Datetime. Why is always …
Let’s start off with that it’s totally possible I overlooked something here. I’m working on NOAA’s tsunami data. I want to combine ‘Year’, ‘Mo’, ‘Dy’, ‘Hr’, ‘Mn’, ‘Sec’ columns together as a datetime. …
Thinking on a MSFT Ignite …
I was watching the Microsoft Ignite event on their event site earlier. It was interesting but not as impactful to me as last year’s Ignite. But there was this thing that Scott Guthrie said something in Microsoft Cloud in the era of AI which grabbed me: GitHub Copilot dramatically accelerates …
Is 'Prompt Engineering' …
We’re still pretty early days in language models, particularly Large Language Models (LLMs). The last year in particular has been pretty crazy. Just under a year ago, on 30 Nov 2022, OpenAI launched ChatGPT – a chatbot wrapped around a OpenAI’s GPT 3.5 model. Just 2 months later …
Sunspots
We have 200 years of daily recording of sun spot data. If you figure a scientist working 25 years, that’s the entire career of eight scientists. More likely though, it’s portion of the careers of lots of scientists – at least up until the point where the collection was automated. I …
One of these things is …
Just to make it clear, this is mostly as a matter of record and as a reminder to myself. I like this hugo theme but there is some excess stuff. I’m not a front-end developer, so it typically takes me a while to figure out what I suppose is a pretty easy thing. Anyway, notice this blue link …
Troubleshooting setup of …
This should probably have been called “Troubleshooting setting up a git repo containing the original files which are then symlinked to …” but that’s way too long. Why I did this: I tried moving all the dot files to a separate folder that I will (eventually) want to set up as …
Heard Back From NGA
Received email from NGA. The answer seemed a mix of low priority, noncommittal, and “this is the way it’s always been done” justifications. I asked for clarification. If this goes nowhere, I’ll make changes and provide them but focus on getting it on Kaggle first. An option …
A Glitchy Detail With …
If you’re using chaining in pandas to pipeline a .csv, order can play a factor. Specifically, with filling in NaNs and reordering column names. It has to be done in that order. So, this works: diamonds = (pd.read_csv("../data/diamonds_raw.csv", index_col=[0]) .drop(['date', …
A Glitchy Detail With …
If you’re using chaining in pandas to pipeline a .csv, order can play a factor. Specifically, with filling in NaNs and reordering column names. It has to be done in that order. So, this works: diamonds = (pd.read_csv("../data/diamonds_raw.csv", index_col=[0]) .drop(['date', …