Projects
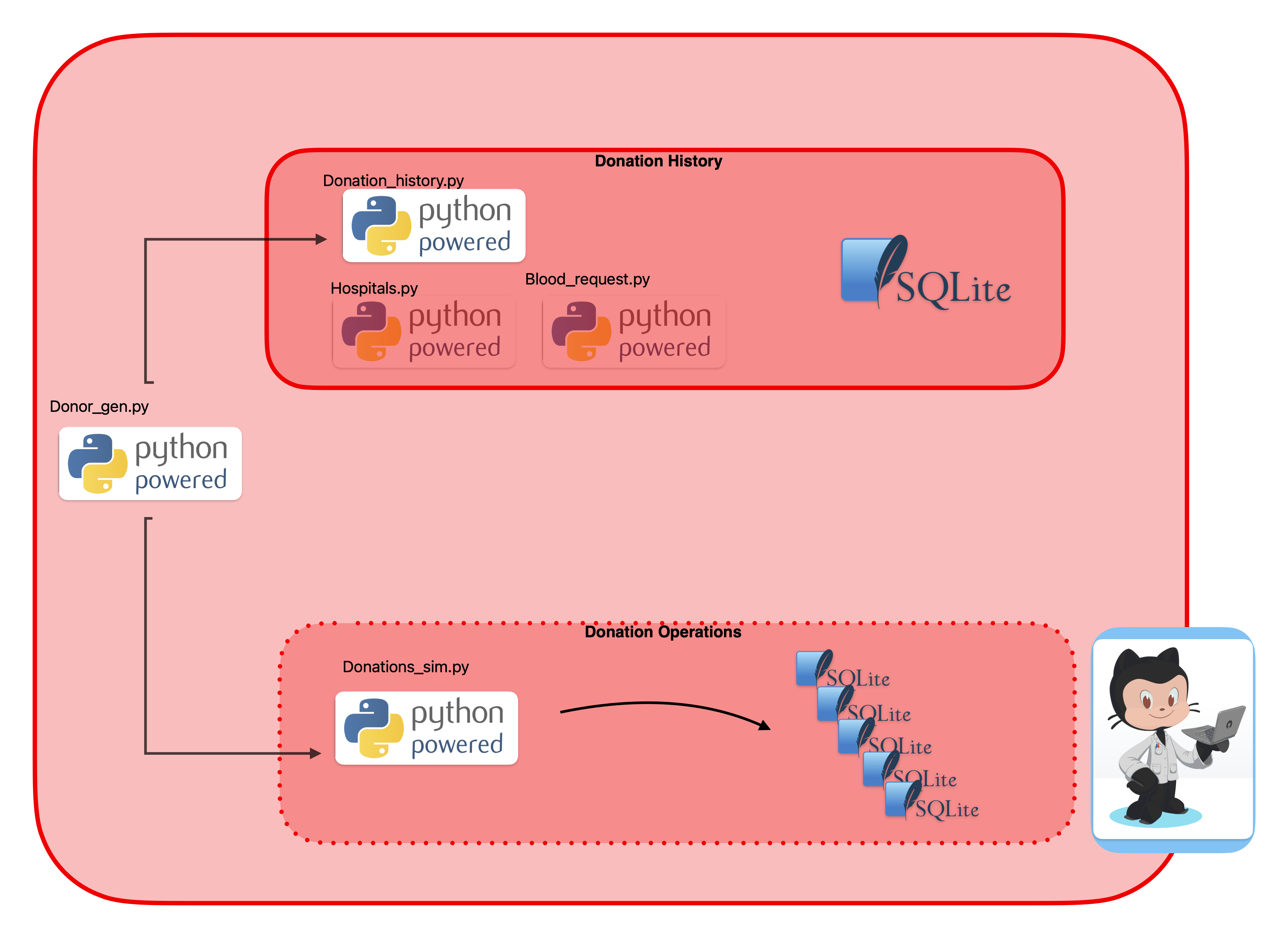
CrimsonCache overview
CrimsonCache generates a synthetic set of blood donors which are then used to populate a MySQL database of blood donations over time. This is for SQL practice. Additionally, there is an update script that generates a much smaller second MySQL database that represent daily donations. This feeds into …
Starting Hemolytics
It might seem a little nuts but I’m starting a sister project for Crimson_Cache. This one will take the SQLite database of donors and ingest it as a Postgres database. It will do the same with the daily blood donations databases. And then a separate (DuckDB) database for analysis. The idea …
Why a Synthetic Dataset
I’m back on CrimsonCache for a while. But it dawned on me that it’s worth laying out my reasons for making a synthetic dataset vs finding one that is real since I have a strong preference for real data. It comes down to four reasons. Overcomes data scarcity. I don’t have access to …
Updating Denver Traffic …
It’s time to update Denver Traffic Accidents on GitHub. The easiest thing would be to do this manually but I don’t want to have to keep doing it, no matter how infrequently. However, there is now a snag that I need to deal with – like IMP the data source has changed somewhat. Both …
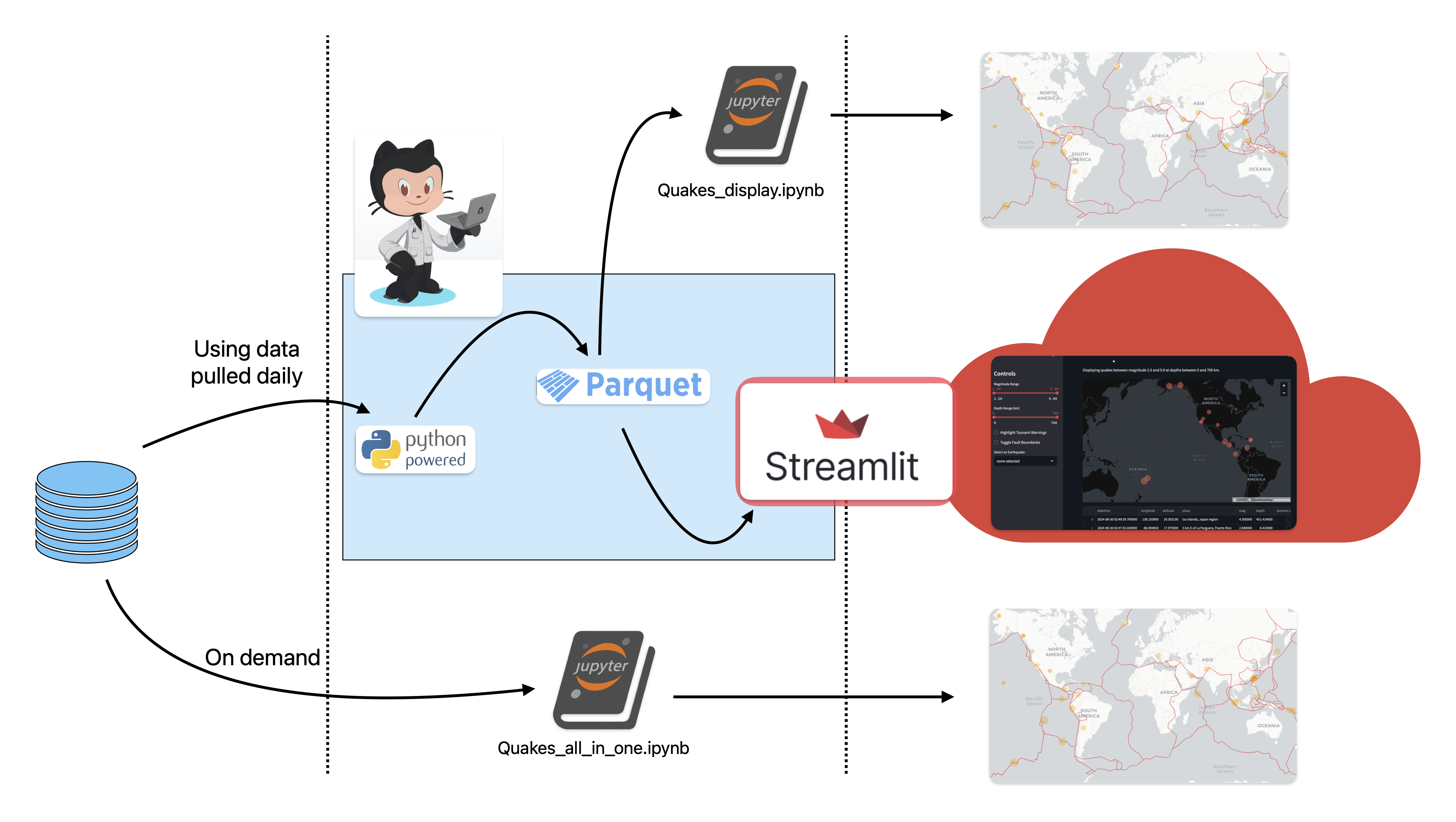
Quakes overview
Quakes is a multipart project that displays earthquakes world wide. Let’s explain it with the graphic above: At midnight, GMT, a GitHub actions creates an ephemeral runner that runs data_processing.py which downloads USGS earthquake data. The data is already clean but needs to be transformed …
A Glitchy Detail With …
If you’re using chaining in pandas to pipeline a .csv, order can play a factor. Specifically, with filling in NaNs and reordering column names. It has to be done in that order. So, this works: diamonds = (pd.read_csv("../data/diamonds_raw.csv", index_col=[0]) .drop(['date', …
A Glitchy Detail With …
If you’re using chaining in pandas to pipeline a .csv, order can play a factor. Specifically, with filling in NaNs and reordering column names. It has to be done in that order. So, this works: diamonds = (pd.read_csv("../data/diamonds_raw.csv", index_col=[0]) .drop(['date', …